Jupyter Snippet CB2nd 07_pca
Jupyter Snippet CB2nd 07_pca
8.7. Reducing the dimensionality of a dataset with a principal component analysis
import numpy as np
import sklearn
import sklearn.decomposition as dec
import sklearn.datasets as ds
import matplotlib.pyplot as plt
%matplotlib inline
iris = ds.load_iris()
X = iris.data
y = iris.target
print(X.shape)
(150, 4)
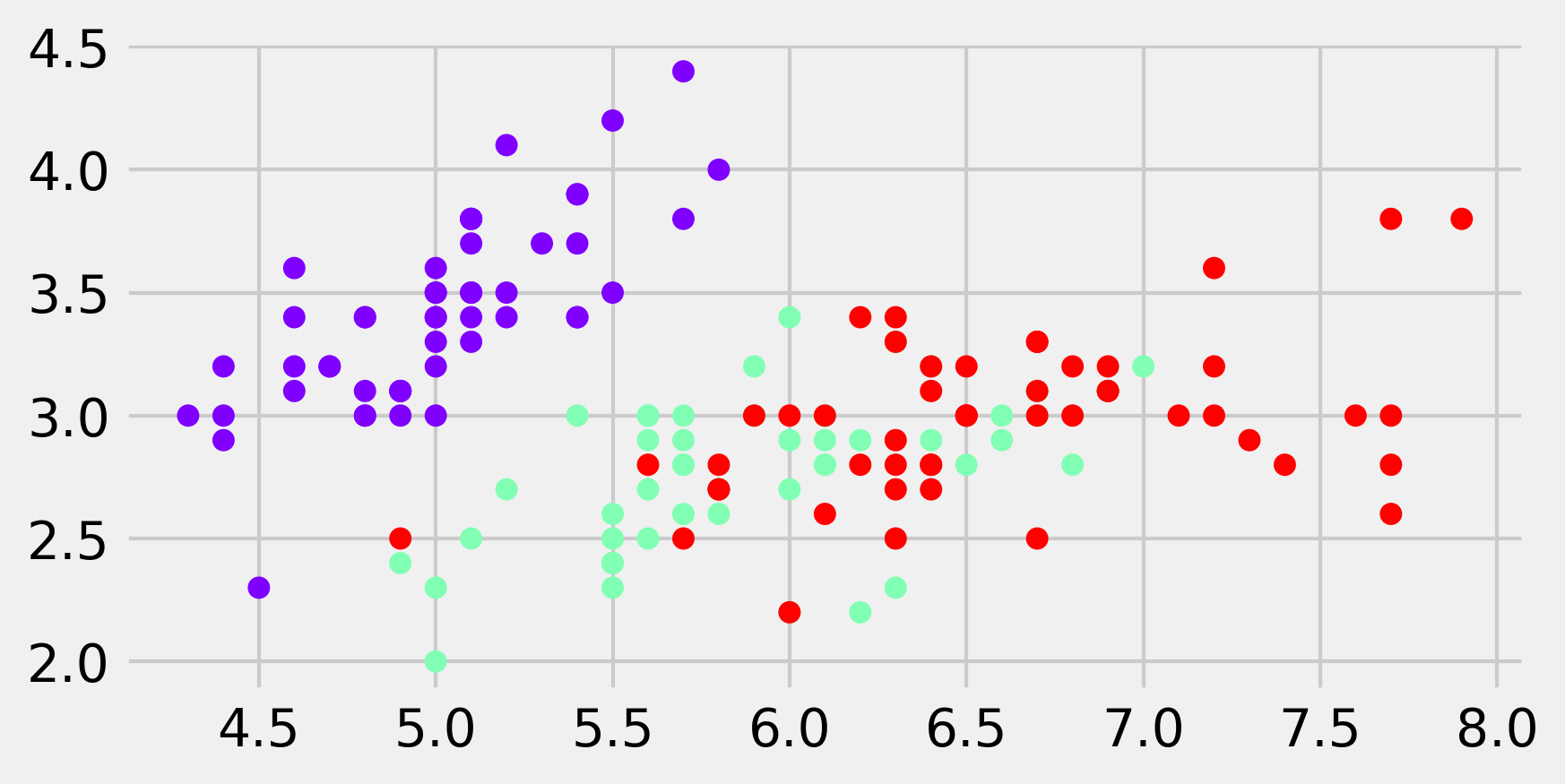
fig, ax = plt.subplots(1, 1, figsize=(6, 3))
ax.scatter(X[:, 0], X[:, 1], c=y,
s=30, cmap=plt.cm.rainbow)
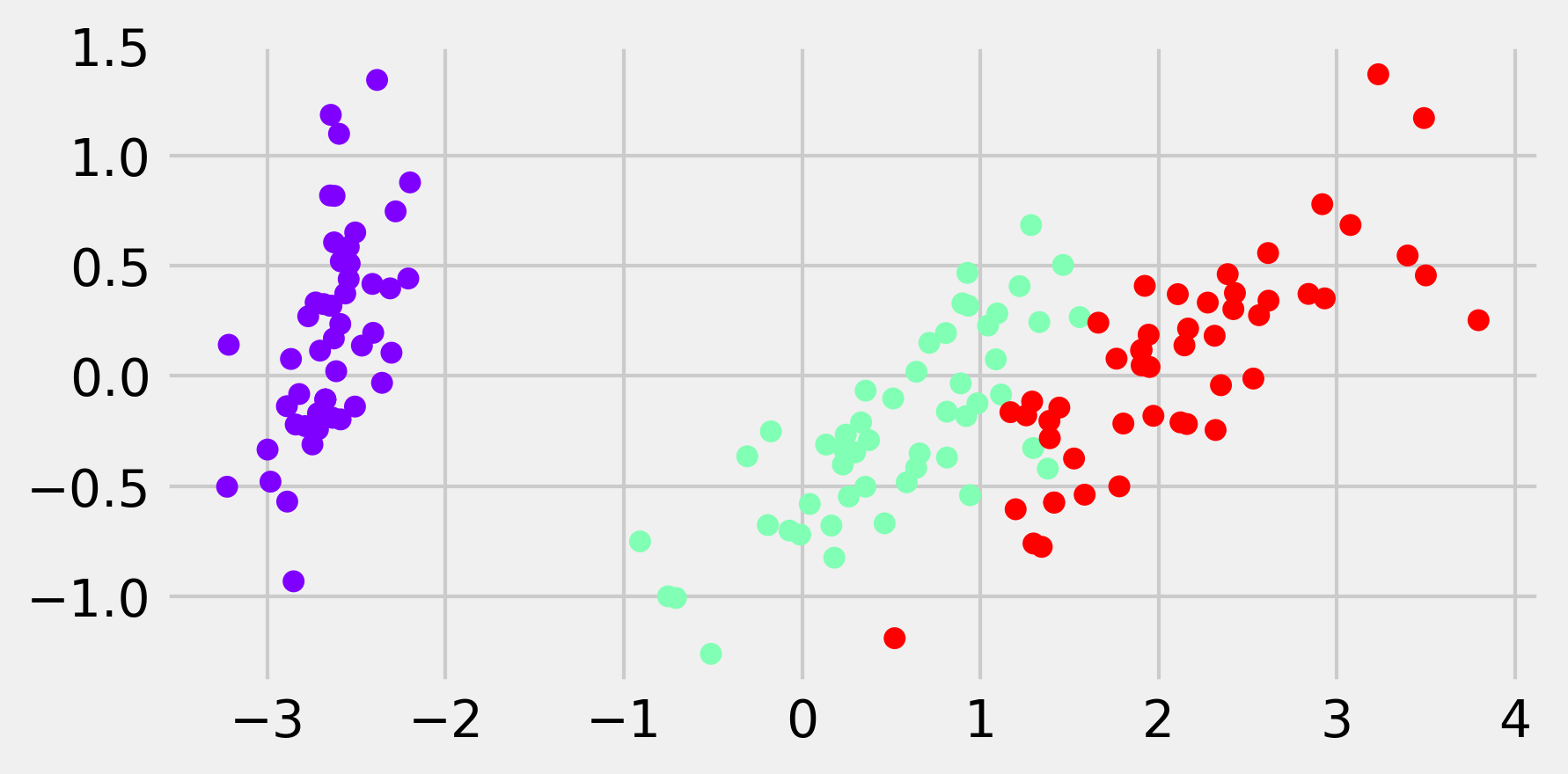
X_bis = dec.PCA().fit_transform(X)
fig, ax = plt.subplots(1, 1, figsize=(6, 3))
ax.scatter(X_bis[:, 0], X_bis[:, 1], c=y,
s=30, cmap=plt.cm.rainbow)
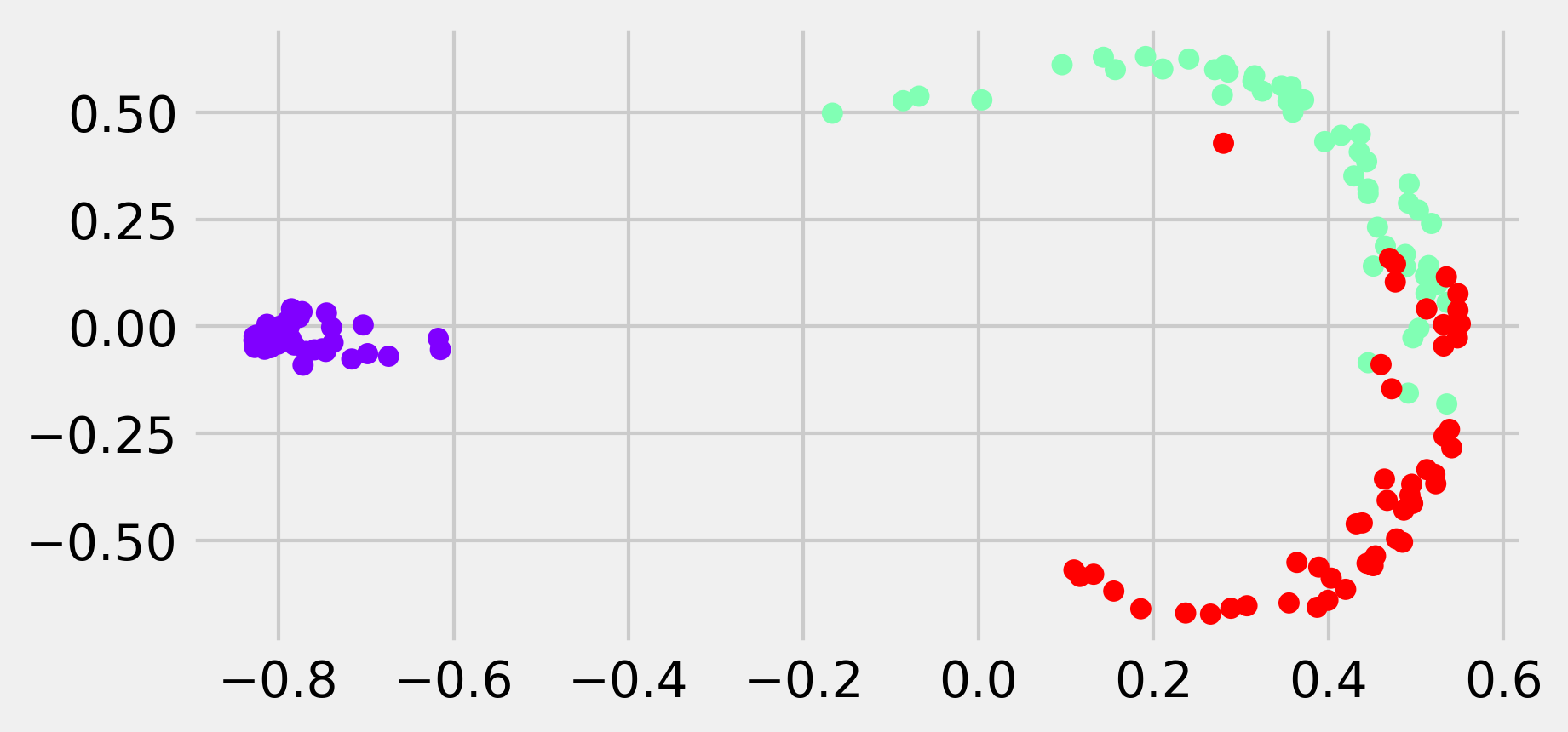
X_ter = dec.KernelPCA(kernel='rbf').fit_transform(X)
fig, ax = plt.subplots(1, 1, figsize=(6, 3))
ax.scatter(X_ter[:, 0], X_ter[:, 1], c=y, s=30,
cmap=plt.cm.rainbow)