Jupyter Snippet CB2nd 06_random_forest
Jupyter Snippet CB2nd 06_random_forest
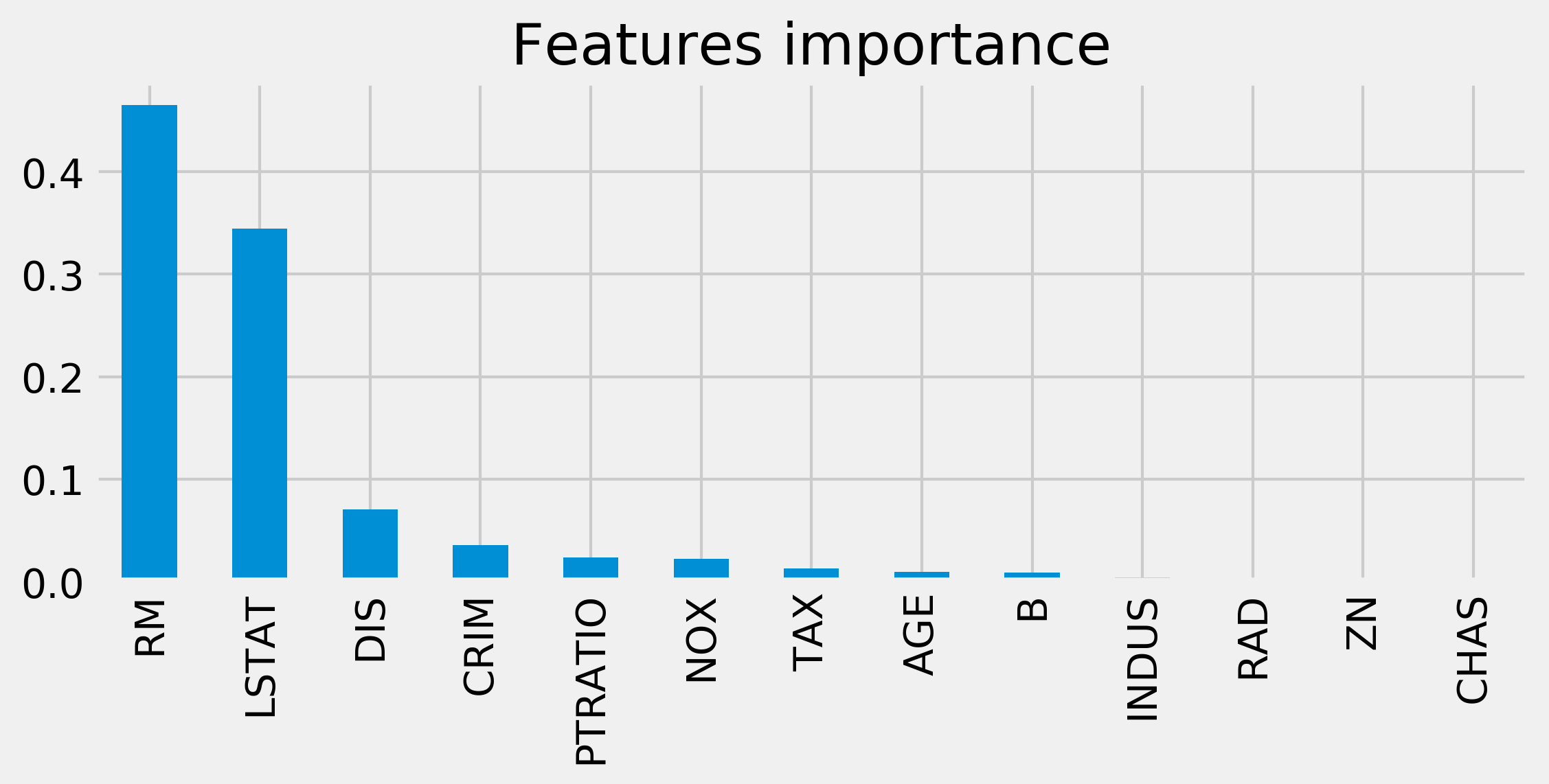
8.6. Using a random forest to select important features for regression
import numpy as np
import sklearn as sk
import sklearn.datasets as skd
import sklearn.ensemble as ske
import matplotlib.pyplot as plt
%matplotlib inline
data = skd.load_boston()
reg = ske.RandomForestRegressor()
X = data['data']
y = data['target']
reg.fit(X, y)
fet_ind = np.argsort(reg.feature_importances_)[::-1]
fet_imp = reg.feature_importances_[fet_ind]
fig, ax = plt.subplots(1, 1, figsize=(8, 3))
labels = data['feature_names'][fet_ind]
pd.Series(fet_imp, index=labels).plot('bar', ax=ax)
ax.set_title('Features importance')
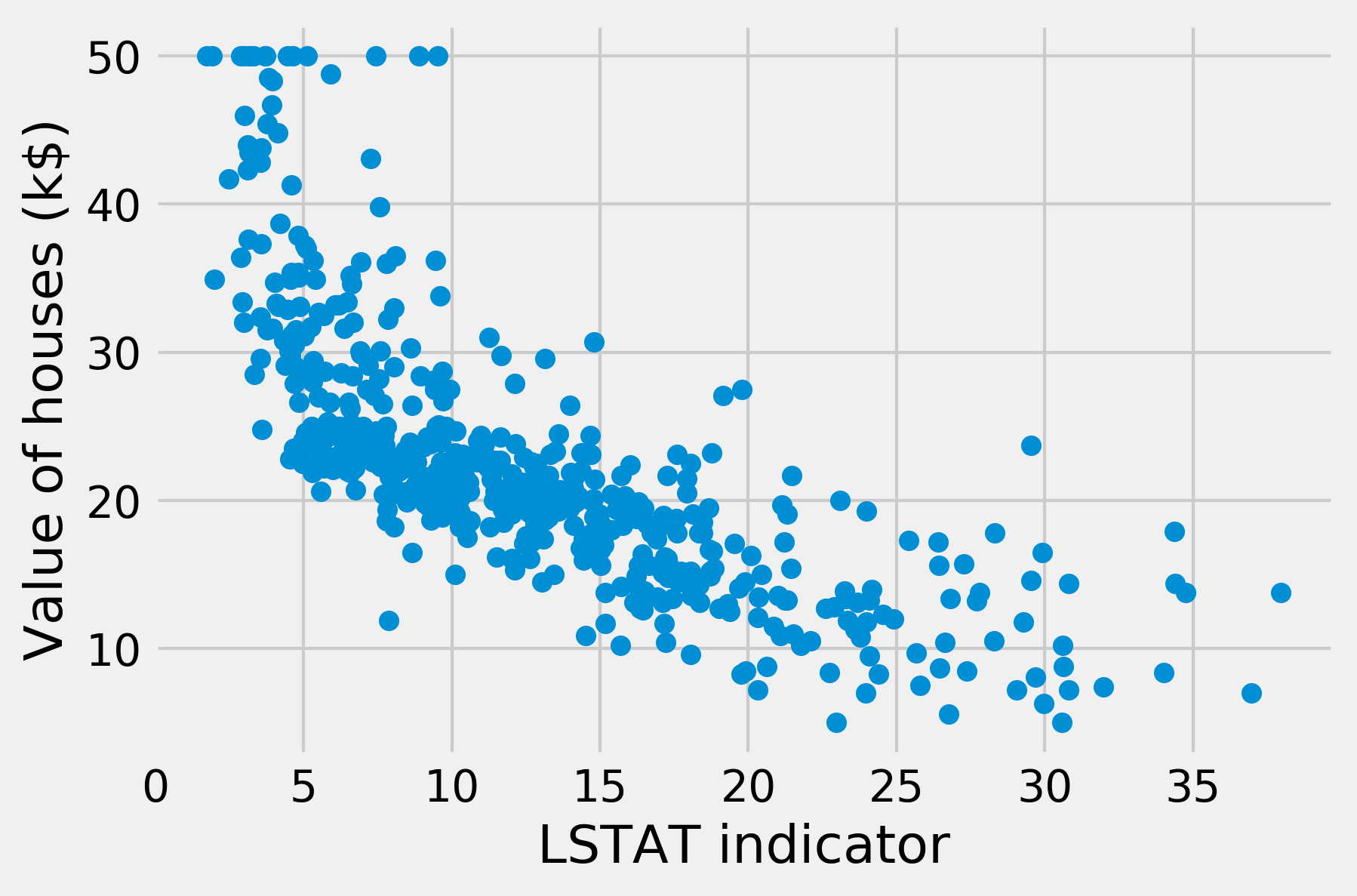
fig, ax = plt.subplots(1, 1)
ax.scatter(X[:, -1], y)
ax.set_xlabel('LSTAT indicator')
ax.set_ylabel('Value of houses (k$)')
from sklearn import tree
tree.export_graphviz(reg.estimators_[0],
'tree.dot')