Jupyter Snippet CB2nd 02_titanic
Jupyter Snippet CB2nd 02_titanic
8.2. Predicting who will survive on the Titanic with logistic regression
import numpy as np
import pandas as pd
import sklearn
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import matplotlib.pyplot as plt
%matplotlib inline
train = pd.read_csv('https://github.com/ipython-books'
'/cookbook-2nd-data/blob/master/'
'titanic_train.csv?raw=true')
test = pd.read_csv('https://github.com/ipython-books/'
'cookbook-2nd-data/blob/master/'
'titanic_test.csv?raw=true')
train[train.columns[[2, 4, 5, 1]]].head()
data = train[['Age', 'Pclass', 'Survived']]
# Add a 'Female' column.
data = data.assign(Female=train['Sex'] == 'female')
# Reorder the columns.
data = data[['Female', 'Age', 'Pclass', 'Survived']]
data = data.dropna()
data.head()
data_np = data.astype(np.int32).values
X = data_np[:, :-1]
y = data_np[:, -1]
# We define a few boolean vectors.
# The first column is 'Female'.
female = X[:, 0] == 1
# The last column is 'Survived'.
survived = y == 1
# This vector contains the age of the passengers.
age = X[:, 1]
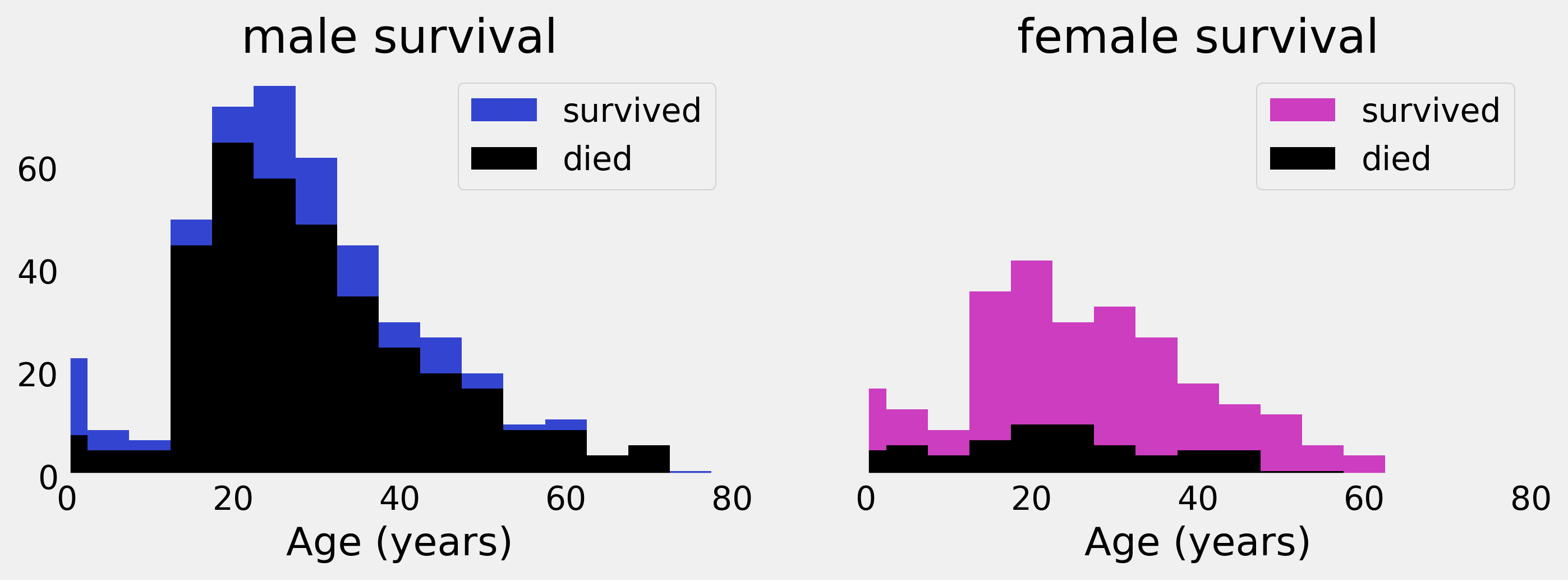
# We compute a few histograms.
bins_ = np.arange(0, 81, 5)
S = {'male': np.histogram(age[survived & ~female],
bins=bins_)[0],
'female': np.histogram(age[survived & female],
bins=bins_)[0]}
D = {'male': np.histogram(age[~survived & ~female],
bins=bins_)[0],
'female': np.histogram(age[~survived & female],
bins=bins_)[0]}
# We now plot the data.
bins = bins_[:-1]
fig, axes = plt.subplots(1, 2, figsize=(10, 3),
sharey=True)
for ax, sex, color in zip(axes, ('male', 'female'),
('#3345d0', '#cc3dc0')):
ax.bar(bins, S[sex], bottom=D[sex], color=color,
width=5, label='survived')
ax.bar(bins, D[sex], color='k',
width=5, label='died')
ax.set_xlim(0, 80)
ax.set_xlabel("Age (years)")
ax.set_title(sex + " survival")
ax.grid(None)
ax.legend()
# We split X and y into train and test datasets.
(X_train, X_test, y_train, y_test) = \
ms.train_test_split(X, y, test_size=.05)
# We instanciate the classifier.
logreg = lm.LogisticRegression()
logreg.fit(X_train, y_train)
y_predicted = logreg.predict(X_test)
fig, ax = plt.subplots(1, 1, figsize=(8, 3))
ax.imshow(np.vstack((y_test, y_predicted)),
interpolation='none', cmap='bone')
ax.set_axis_off()
ax.set_title("Actual and predicted survival outcomes "
"on the test set")

ms.cross_val_score(logreg, X, y)
array([ 0.78661088, 0.78991597, 0.78059072])
grid = ms.GridSearchCV(
logreg, {'C': np.logspace(-5, 5, 200)}, n_jobs=4)
grid.fit(X_train, y_train)
grid.best_params_
{'C': 0.042}
ms.cross_val_score(grid.best_estimator_, X, y)
array([ 0.77405858, 0.80672269, 0.78902954])